南京大学软件学院-2025Fall-统计模型(研究生)期末复习参考
建议《统计模型:理论与实践》跟《数据仓库与知识发现》一块选,这两门课有些知识点是重复的。虽然考试时间可能挨得比较近。
- 闭卷考试,但《统计模型》考试难度不高,只要把关键的知识点复习好了就没问题
- 部分内容使用AI生成,仅供参考。
- 感谢往年学长/学姐的博客帮助复习和整理:jinqiqing 的博客
2025FALL真题(回忆版)
一、简答:
- 聚类的评价标准
- 举例说明EM算法的应用场景
- 训练集、验证集、测试集的作用与区别
- C4.5比ID3改进的点
- 写出正态分布的概率密度函数及参数的含义
- TF-IDF与主题模型的关系
- 写出典型的NLP任务及其特征应用(我不太懂这个“及其特征应用”是让写啥的?)
- 什么是词项-文档矩阵,构造过程是什么
二、计算:
- K-means的一次迭代(分簇结果,和新的中心点)
- 写出正态分布的似然函数、对数似然函数,求偏导求参数的最大似然估计
- 朴素贝叶斯计算
- Gamma函数的计算Gamma(4)的值和自然数时Gamma函数表现为阶乘的推导
- 词袋模型,给定两个句子,进行词袋模型构造,最后给出两个句子的向量
一、聚类分析
(一)概念
1.聚类问题的定义
给定一组点,以及点之间的距离概念,将这些点分组为若干clusters,使得
- cluster中的成员彼此接近/相似
- 不同cluster的成员之间不相似
通常:
- 这些点位于高维空间中
- 相似性使用距离来度量( 欧几里得距离、 余弦相似度、杰卡德相似度、编辑距离等)
2.硬聚类和软聚类
硬聚类:每个数据点仅属于一个聚类
软聚类:每个数据点可以属于多个聚类
3.什么是聚类
- 将数据组织成类别,使其存在高类内相似度和低类间相似度
- 直接从数据中数据中寻找类别标签和类别数量
- 在对象间寻找自然的组群
4.什么是启发式方法
启发式方法(heuristics)用于快速得出一个接近最佳可能答案或“最优解”的解决方案。启发式是一种“经验法则”,一种有根据的猜测,一种直觉判断,或者仅仅是常识。
如仿动物类算法、仿植物类算法、仿人类的算法
(二)聚类方法论
主流的聚类算法可以分成两类:划分聚类(Partitioning Clustering,层次聚类)和层次聚类(Hierarchical Clustering)。
1.K-Means
1.1.K-Means的概念
聚类算法要把 个数据点按照分布分成
类(很多算法的
是人为提前设定的)。我们希望通过聚类算法得到
个中心点,以及每个数据点属于哪个中心点的划分。
1.2.K-Means的流程
- 选择簇的数量 k,一般人为规定;还要确定距离计算方法(如欧几里得距离)。
- 初始化簇:随机选择 k 个点作为初始簇的质心。常见的初始化方法是随机选择一个点,然后选择 k-1 个其他点,每次选择的点尽量远离前面已选择的点。
- 分配点到簇:对于数据集中的每个点,将其分配到距离当前簇质心最近的簇。
- 更新簇的质心:在所有点分配完毕后,计算每个簇中所有点的均值,并更新簇的质心位置。
- 重新分配点:根据新的质心位置,重新将所有点分配给最近的质心。这一步可能会导致某些点从一个簇移到另一个簇。
- 重复步骤 4 和 5,直到收敛。收敛条件::点不再在簇之间移动,并且质心位置趋于稳定。
可能的终止条件:
- 固定次数的迭代
- 数据点分区不再变化
- 质心位置不再变化。
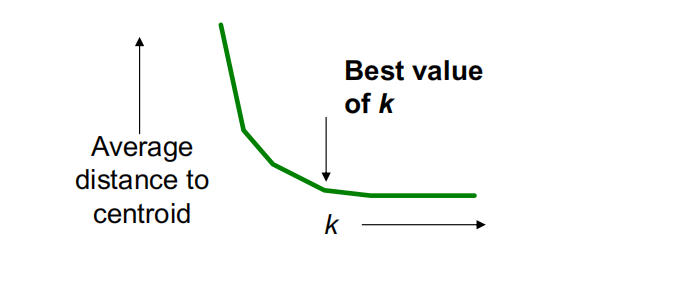
如何选择K?
不同的k值,观察随着k增加,到质心的平均距离的变化情况。平均值在达到正确的k之前迅速下降,之后变化不大。
1.3.K-Means的优缺点
优点:
- 相对高效:时间复杂度O(tkn),其中n为对象数量,k为聚类数量,t 为迭代次数。通常,k、t «n。相比层次聚类的复杂度通常是 O(n^2)$ 或 O(n^3)。
- 通常收敛于局部最优:它每一步都寻找当前看来最好的结果,全局最优可以借助模拟退火和遗传算法实现。
缺点:
- 均值定义的局限性:仅适用于可以计算“平均值”的数据。如果你的数据包含分类型变量(Categorical Data),比如“颜色(红、蓝、绿)”或“职业”,你是无法计算“红色和蓝色的平均值”的。对于分类数据,通常改用 K-modes 算法(使用众数而非均值)。
- 必须预先指定 K 值
- 对噪声和离群点敏感
- 无法处理非凸形状的聚类:K-means 本质上是基于欧氏距离的,它倾向于寻找球形(Spherical)或凸多面体结构的簇。它假设簇是从一个中心向外均匀扩散的。
2.层次聚类
2.1.层次聚类的概念
层次聚类会输出一个具有层次结构的簇集合,因此能够比划分聚类输出的无结构簇集合提供更丰富的信息。层次聚类可以认为是是嵌套的划分聚类。
它使用距离矩阵作为聚类标准。这种方法不需要聚类数量k作为输入,但需要一个终止条件。
一般实现:在每一步中,计算所有聚类对之间的成对距离,然后合并,复杂度 O(N^3)
使用优先级队列可以降到O(N^2logN),这个时间复杂度还是很高的
2.2.层次聚类的类型
- 凝聚型或自下而上的方法:最初每个点都是一个聚类,然后反复将簇合并成更大的簇,直到形成一个单个簇。
- 分裂型或自上而下的方法:从单个簇包含所有数据开始,然后继续递归的划分,直到所有的簇都是单一簇。
2.3.层次聚类的关键问题
2.3.1.如何表示包含多个点的簇?
问题:在合并聚类时,如何表示每个聚类的“位置”,以判断哪一对聚类距离最近?
欧几里得情形:每个簇有数据点的 centroid = 平均值,即质点代表聚类的位置。
非欧式情况:中心点clustroid=最近接簇中所有其他点的点,度量方式:
- 到其他点的最大距离最小
- 到其他点的平均距离最小
- 到其他点的距离平方和最小
2.3.2. 如何确定聚类之间的“邻近度”?
欧几里得情况:使用质心的距离度量聚类间距
非欧几里得的情况:
- 最小(单一)链接:单一连锁准则方法会分析两个簇中的项之间的间距,然后使用簇之间的最小距离。最小方法可以很好地处理非椭圆的簇形状,但会受到噪声和异常值的影响。
- 最大(完整)链接:簇距离也可以基于彼此最远的数据点来计算。与最小距离法相比,最大距离法对噪声和异常值的敏感度较低,但在存在球状或较大簇时,使用最大距离法可能会导致结果偏差。最大连锁准则通常比最小连锁准则产生更接近球形的簇。
- 平均链接:将簇之间的距离定义为簇中所有点对中的对之间的平均距离。
2.3.3. 何时停止合并聚类?
层次聚类默认会一直合并,直到最后只剩下一个包含所有点的“大簇”。在实践中,我们需要根据以下准则提前停止:
预设簇数K:根据先验知识确定
距离阈值:设定一个临界值 tau,如果当前最邻近的两个簇之间的距离已经超过了tau,则认为这两个簇不属于同一类,停止合并。
谱系图/树状图分析:观察树状图,找到垂直跨度最长(即合并距离跨度最大)的地方横切一刀。这一刀所经过的竖线数量就是最优的K值。
统计学指标:计算每个层级的不一致系数,当该系数突然增大时,说明合并质量急剧下降,应在此处停止。
2.4.层次聚类的优缺点
优点:
- 无需预设簇数k
- 直观的层次结构
- 度量准则灵活
- 空间适应性强
- 多种邻近度定义
缺点:
- 终止条件模糊
- 计算复杂度较高
- 决策不可逆性
- 对特定形状或噪声敏感
- 表示点的局限性
3.密度聚类
4.评价聚类的好坏
4.1.内部标准
一个好的聚类方法将产生高质量的簇,其中:簇内相似度高;簇间相似度低。聚类质量的结果既取决于数据的表示方式,也取决于相似性的度量方法。
4.2.外部标准
- 质量评估:聚类的质量通过其发现隐藏模式或潜在类别的能力来衡量,这些模式或类别通常是基于gold standard data的。
- 基于真实标签评估聚类:通过与真实数据进行比较来评估聚类的效果,这意味着需要有标签的数据。
4.3.计算纯度

4.4.兰德指数 (Rand Index, RI)


二、EM算法
(一)预备知识
1.极大似然估计
似然函数:对于一种操作的结果(比如抛硬币),我们观察到了一组数据,似然函数表示在给定参数p的情况下,观测到当前数据的概率是多少。
极大似然估计的目的:在所有可能得参数中,找到一个使得在该参数下,观测到的数据最有可能发生。


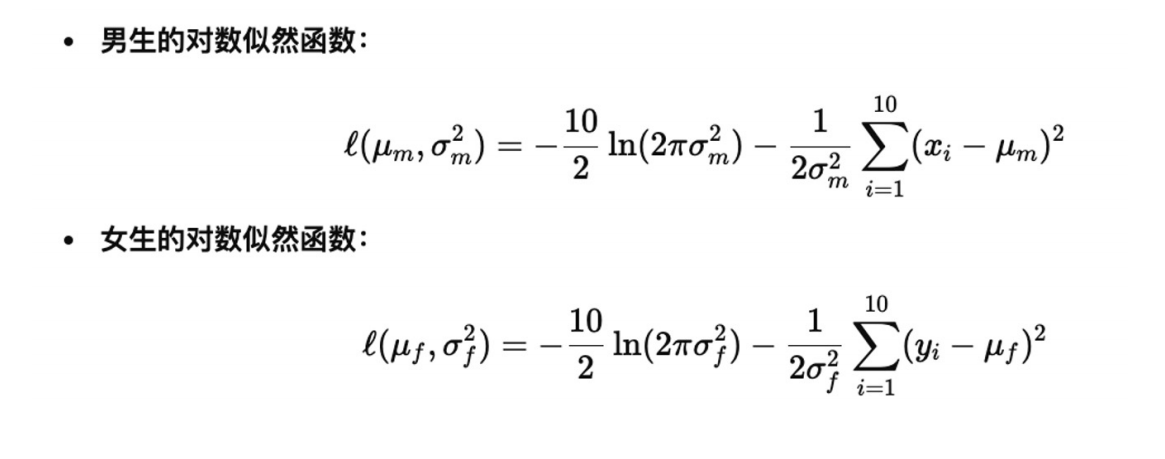


然后就是根据观测数据,计算相应的均值和方差即可。
2.Jensen不等式
Jensen 不等式是数学分析和概率论中的⼀个重要不等式,描述了凸(或凹)函数与随机变量期望之间的关系。简单来说,它揭示了在凸函数下,函数作用于期望值小于等于期望值作用于函数。


(二)EM(Exception-Maximization Algorithm,期望最大化算法)
1.EM的概念
EM是一种用于含有隐变量或不完全数据的概率模型中寻找参数最大似然估计的迭代算法。
E步(期望步):根据当前参数估计,计算隐含数据的期望值
M步(最大化步):最大化期望值的函数,更新参数估计
EM算法的目标:最大化观测数据的对数似然函数:ln p(X;θ),X是观测数据,θ是待估计的参数。


2.EM算法步骤

EM的使用场景
- 含有隐变量的模型: 如高斯混合模型(GMM)、隐马尔可夫模型(HMM)等。
- 不完全数据:数据集中存在缺失值,需要估计缺失部分
- 参数估计困难: 直接最大化似然函数过于复杂或不可行。
3.应用:混合高斯模型
4.EM算法的优缺点

5.其他应用
聚类分析、缺失数据的处理、隐马尔可夫模型、图像分割等
三、分类算法
(一)概念
1.什么是分类
给定一个带标签实体的训练集,制定一个规则,用于为测试集中的实体分配标签。
2.分类算法的应用场景
垃圾邮件过滤、数字识别、欺诈检测、网页垃圾检测、语音识别和说话者识别、医学诊断、自动论文评分、电子邮件路由、社交网络中的链接预测、药物设计中的催化活性
3.一些名词
数据集
- 训练集: 用于模型拟合的数据样本, 模型通过这些数据计算梯度,使用梯度下降等算法来更新模型内部的权重/参数
- 验证集: 用于模型优选和超参数调整的数据样本,模型不会利用它来更新权重,用它来观察模型是否过拟合。如果模型在训练集表现极好,但在验证集表现变差,说明模型“死记硬背”了,这时需要停止训练或调整正则化参数。
- 测试集:仅用于最终评估模型性能的数据样本,在模型开发完全结束前,绝对不能让模型看到测试集的数据。
一些分类器:支持向量机、随机森林、核化逻辑回归、核化判别分析、核化感知器、贝叶斯分类器
常用的分类方法
贝叶斯、决策树、支持向量机、K近邻、逻辑回归、神经网络、深度学习、集成学习
(二)算法
1.贝叶斯
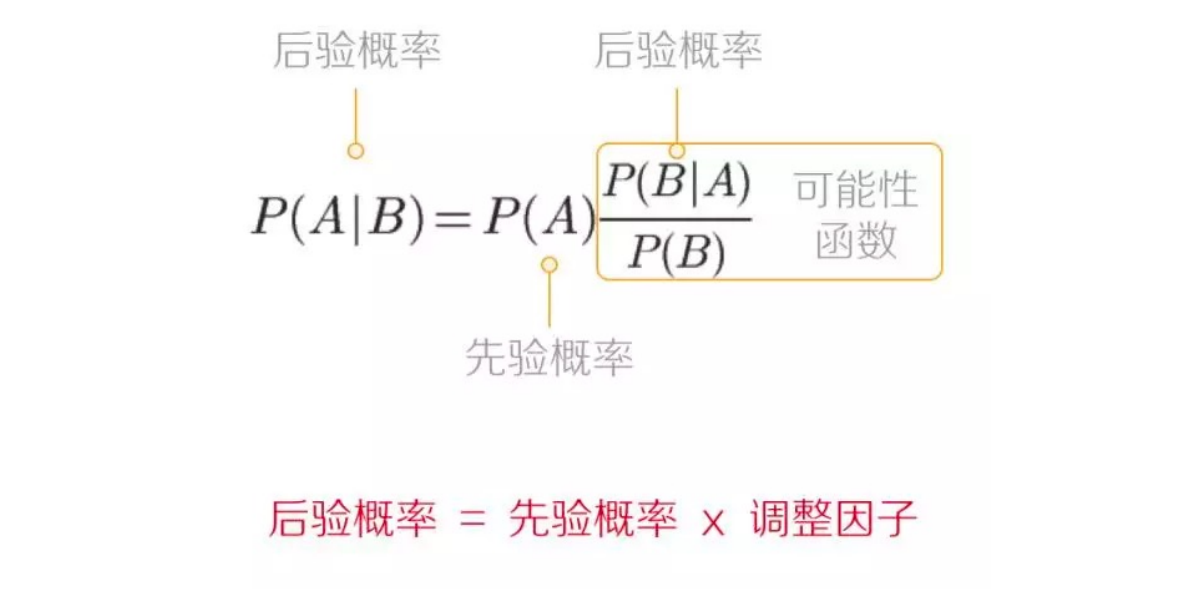
1.1.条件概率
| 条件概率是指在事件B发生的情况下,事件A发生的概率,用P(A | B)表示,读作在B条件下的A的概率。 |
1.2.全概率
如果事件 A1,A2,…,An 构成一个完备事件且都有正概率,那么对于任意一个事件B则有:

1.3.贝叶斯公式
1.4朴素贝叶斯
朴素贝叶斯基于假设:x1,x2…xn之间独立

考点:朴素贝叶斯公式,分母用全概率公式计算
2.决策树
2.1.决策树的概念
决策树由结点和有向边组成,结点氛围内部节点和叶节点,内部节点表示一个特征,叶节点表示一个类。
2.2.ID3算法
核心思想是:在每一次决策中,贪心地选择那个能让数据“最快变纯净”的特征进行分裂。
2.2.1相关概念
信息熵:熵是衡量数据混乱程度或不确定性的指标

信息增益:如果我用特征A对数据集S进行划分,数据的混乱程度(熵)减少了多少?
增益 = 分裂前的熵 - 分裂后的加权平均熵
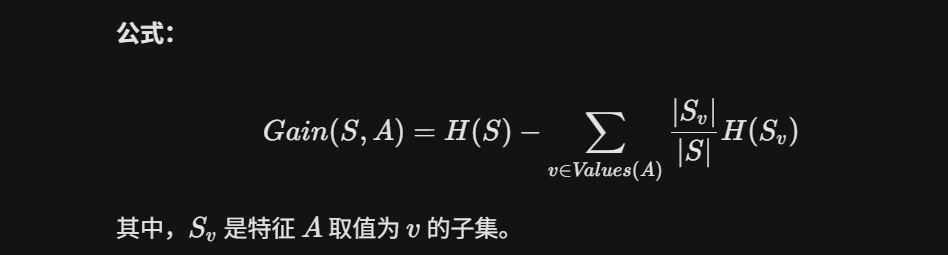
ID3 的策略:计算所有特征的信息增益,选择增益最大的那个作为当前节点。
2.2.2ID3算法步骤
- 使用所有没有使用的属性并计算与之相关的样本熵值
- 选取其中熵值最小的属性
- 生成包含该属性的节点
2.2.4计算示例


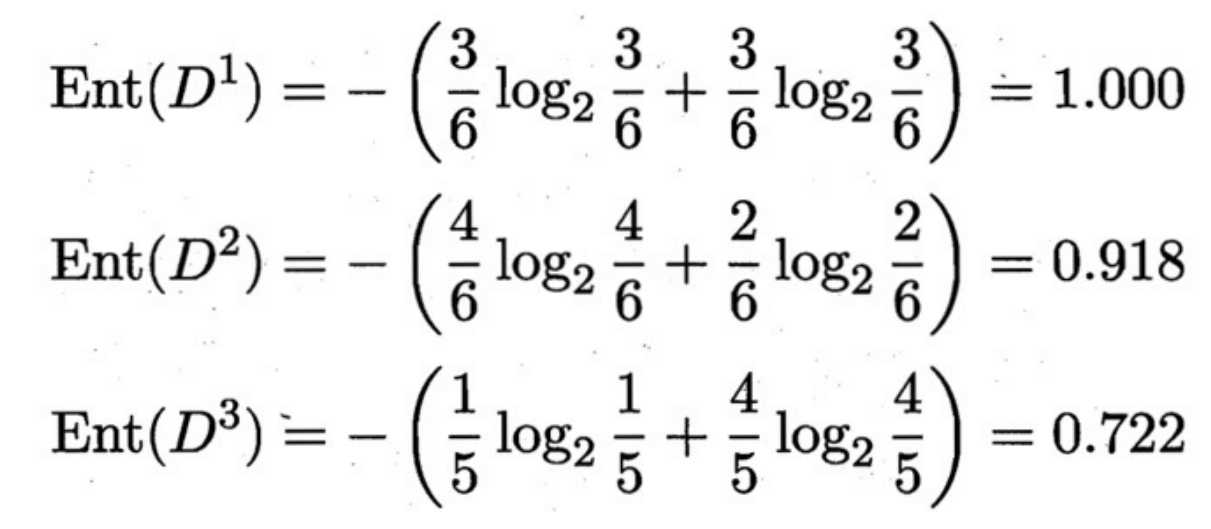


信息增益最大的是纹理,所以先根据纹理进行划分
2.3.C4.5算法
C4.5算法是对ID3算法的改进,C4.5克服了ID3的两个缺点:
- 用信息增益选择属性时偏向于选择分枝较多的属性值,即取值多的属性
- 不能处理连续属性
C4.5的做法:C4.5 引入了一个新的指标叫 信息增益率,用来“惩罚”那些取值太多的特征。

四、Gamma函数
Gamma 函数的诞生是为了解决一个历史性难题:如何将阶乘的概念推广到非整数(如实数甚至复数)领域。
Gamma函数的表示形式: \(\Gamma(z) = \int_{0}^{\infty} t^{z-1} e^{-t} dt \quad (z>0)\) Gamma函数的递推公式,这个公式可以使用分部积分证明 \(\Gamma(\alpha+1) = \alpha \Gamma(\alpha)\) 当变量n为自然数时: \(\Gamma(n) = (n-1)!\) 特殊值: \(\Gamma\left(\frac{1}{2}\right) = \sqrt{\pi}\) 例题
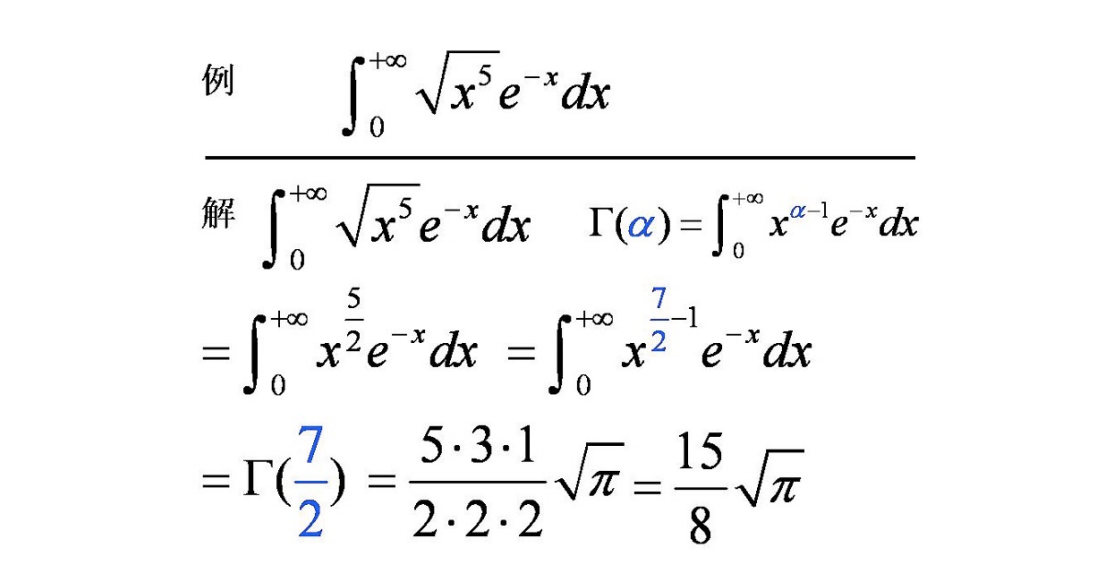
五、分布
1.二项分布
适用场景: 重复n次独立的伯努利试验(结果只有成功/失败),每次成功概率p恒定 1。例如:抽样质检、抛硬币。
公式: \(P(X=x) = \binom{n}{x}p^{x}(1-p)^{n-x}\) 其中系数其实就是n中挑出来x个的个数 \(\binom{n}{x} = \frac{n!}{x!(n-x)!}\) x表示成功结果的数量;n表示总实验数;p表示成功的概率
期望与方差 \(E(X) = np, \quad Var(X) = np(1-p) = npq\) 近似条件:
当 p趋近于0且n趋近于正无穷时,近似为泊松分布
当p<=0.5且np>5或p>0.5且nq>5时,近似为 正态分布 5。
2.泊松分布
适用场景: 某时间段或空间内,稀有事件发生的次数。事件独立且发生率恒定 。例如:药物过敏人数。
数学模型: \(P(X=k) = \frac{e^{-\lambda}\lambda^k}{k!}\) k表示事件发生的次数;λ表示平均事件发生次数
期望与方差(特征:均值等于方差): \(E(X) = Var(X) = \lambda\) 近似条件: 当λ> 5时,可近似为正态分布
计算:
题目:n=1000人,过敏率p=0.001。求>=2人过敏的概率? \(先算均值:\lambda = np = 1000 \times 0.001 = 1\)
\[求:P(X \ge 2) = 1 - P(X \le 1) =\] \[1 - (P(0) + P(1))=1 - \left( \frac{e^{-1}1^0}{0!} + \frac{e^{-1}1^1}{1!} \right) = 0.264\]3.指数分布
适用场景: 描述两个独立事件发生的时间间隔或距离 。它与泊松分布紧密相关。
数学模型: \(f(x) = \lambda e^{-\lambda x}\) 其中λ是泊松分布的均值;x事件发生间隔的长度
期望与方差: \(E(X) = \frac{1}{\lambda}, \quad Var(X) = \frac{1}{\lambda^2}\) 累积分布函数 (必背!用于计算): \(F(x \le k) = 1 - e^{-\lambda k}\) 使用场景:测量误差、自然现象
计算:灯泡平均寿命μ= 1000小时。求寿命> 1000小时的概率。 \(首先计算:\lambda = 1/\mu = 0.001\)
\[P(X > 1000) = 1 - F(1000) = 1 - (1 - e^{-0.001 \times 1000}) = e^{-1} = 0.368\]4.正态(高斯)分布
正态分布,也称高斯分布,是统计学中最重要的一种连续型概率分布。它经常用于描述自然界中的随机现象,如身高、体重、考试成绩等变量的分布。
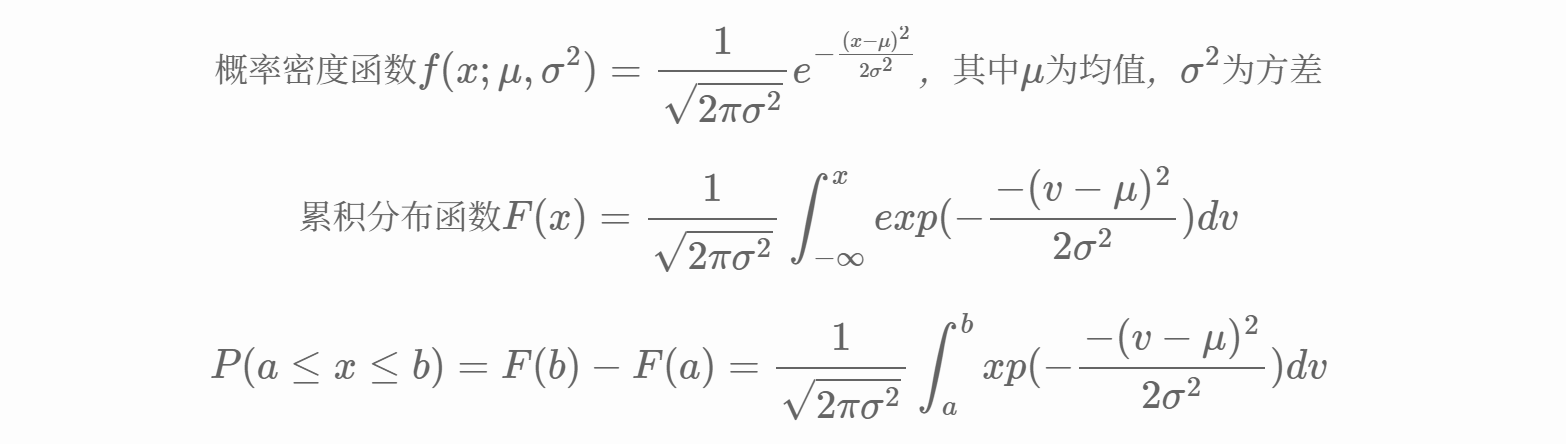

5.Beta分布(应该不考)
适用场景: 变量被限制在区间(通常是 0 到 1)内,常用于建模比例 (Proportions) 或概率 。常用于贝叶斯分析和PERT网络 。
模型特征:两端有界变量;多种分布形状;事件是独立的;模型比例

一般令w0=0.w1=1


六、NLP基础
(一)自然语言
1.自然语言的特征
- 基于规则的特征
- 固定的语法结构或词性分布
- 固定的谓词逻辑规则
- 通用的前缀、后缀
- 基于统计的特征
- 基于大规模语料的特征, 如频率特征
- 基于词的编辑距离衡量的词相似性度量
- 基于语言结构的特征
- 词性特征
- 命名实体特征
- 其他可用特征
- 词频特征
- 词的共现频率(见N-Gram)
- 虚词个数
- 词性特征
- 句子的句法、文法特征
- 句子长度
- 词编辑距离特征等
- 词情感特征(否定、肯定等)
2.常见的NLP任务
垃圾邮件、短信识别
文本相似性判断,用于文本聚类或信息检索
文本情感分析
文本质量评估
文本主题提取
3.如何提取特征——分词
3.1分词的概念
分词,即利用计算机技术将连续的字序列按照一定的规范重新组合成词序列的过程,其通常见于中文文本处理,由于英文文本可直接采用空格作为分隔符对词进行切分。
例:汽水不如果汁好喝
分词结果:汽水/ 不如/ 果汁/ 好喝/
3.2.分词算法
现有的分词算法可分为三大类:
- 基于字符串匹配的分词方法
- 正向最大匹配法(由左到右的方向)
- 逆向最大匹配法(由右向左的方向)
- 最少切分
- 双向最大匹配法
- 基于理解的分词方法
- 基于统计的分词方法。
3.2.1.基于字符的匹配算法
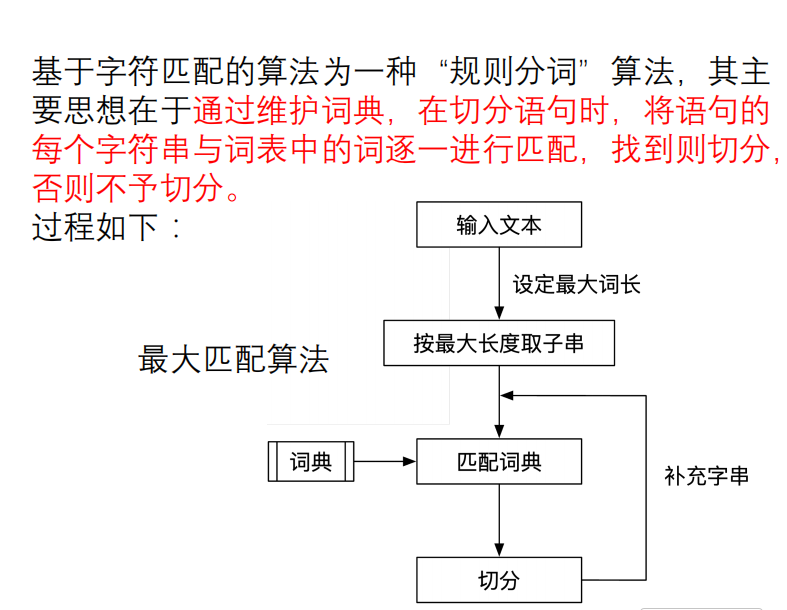
正向最大匹配:

逆向最大匹配:

双向最大匹配::将正向最大匹配法与逆向最大匹配法组合。先根据标点对文档进行粗切分,把文档分解成若干个句子,然后再对这些句子用正向最大匹配法和逆向最大匹配法进行扫描切分。如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按最小集处理(最少切分)。
最佳匹配算法:在词典中按词频的大小顺序排列词条,以求缩短对分词词典的检索时间,达到最佳效果,从而降低分词的时间复杂度,加快分词速度。
3.2.2.基于理解的分词方法(基于人工智能的分词)
其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统和总控部分。通常有如下几种方法:
- 专家系统分词法
- 神经网络分词法
- 神经网络专家系统集成式分词法
3.2.3.基于统计的分词
基于统计的方法思想为:词是稳定的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻出现的概率或频率能较好反映成词的可信度。可以对训练文本中相邻出现的各个字的组合的频度进行统计,计算它们之间的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可以认为此字组可能构成了一个词。该方法又称为无字典分词。
主要统计模型:N 元文法模型、隐Markov模型和最大熵模型等。在实际应用中一般是将其与基于词典的分词方法结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
3.2.4什么是停用词
- 功能词:‘the’、‘is’、‘at’、‘which’、‘on‘、的、是等;
- 词汇词:’want‘等

3.2.5命名实体识别(Named Entity Recognition,NRE)
所谓的命名实体就是人名、机构名、地名以及其他所有以名称为标识的实体,也包括日期、货币等。命名实体的定义与其处理的问题有关,如在医学领域,药物名、疾病名也是命名实体。
问题1:如何确定汉语的实体边界?问题2:如何将可能的实体,划分到正确的类别中?
方法:
- 基于规则的NRE:借助语言学专家,对自然语言中命名实体出现的规则进行总结,并编写模板,使用模板匹配实体。
- 弊端:仅适用于规律确定的实体;需要领域专家制定规则;规则不全面,无法最大限度识别实体
- 基于统计:避免了规则的构造和提取;利用统计规律,更具通用性;统计模型更加容易实现自动化。
3.2.6词性(Part of Speech Tagging,POS)
词性(POS):指以词的特点作为划分词类的根据。词类是一个语言学术语,是一种语言中词的语法分类,是以语法特征(包括句法功能和形态变化)为主要依据、兼顾词汇意义对词进行划分的结果。
方法:规则匹配、隐马尔可夫、条件随机场
(二)算法
1.Markov Chain(马尔可夫链)
马尔可夫链是概率论和数理统计中具有马尔可夫性质且存在于离散的指数集和状态空间内的随机过程。在马尔科夫链中,通常可用于从当前的状态,计算未来状态的概率。
马尔科夫假设:系统的下一个状态,只取决于当前的状态,而与过去更早的状态无关。

2.N-Gram Model
是基于马尔科夫假设的语言模型(Language Model)。它的任务是:给定前面的单词,预测下一个单词出现的概率。
N-Gram模型关注的主要特征为词的共现特征,即共现频率高的多个字其更有可能组成一个词,如“人”和“民”,其通常一起出现,被称为共现,因此“人民”可作为一个词的切分。因此N-Gram需要能够计算词的共现频率,来判断该词能不能作为整体切分。

基于马尔科夫假设得到的模型:
| 模型名称 | N 的值 | 马尔科夫阶数 | 假设:下一个词取决于… |
|---|---|---|---|
| Unigram (一元) | N=1 | 0阶 (独立) | 不看历史,只看词频。 |
| Bigram (二元) | N=2 | 1阶 | 只取决于前 1 个词。 |
| Trigram (三元) | N=3 | 2阶 | 只取决于前 2 个词。 |

3.隐马尔可夫模型
4.词间相似性
4.1.闵可夫斯基距离
4.2.词的编辑距离
词的编辑距离,描述了一个词变为另一个词所需的操作次数,从某种程度而言,可以作为词于词之间的相似性。但编辑距离的概念对于中文无较好支持。
5.词向量技术(Word Vector)/词嵌入
词向量化技术(在深度学习领域通常称为词嵌入),能够将自然语言中的词转化为可供计算的数学表示(通常是向量)。若考虑向量的维度为𝑚,则可以使用𝑚范数距离计算向量之间的距离,表示词间距离。
常用技术:One-Hot、词袋模型(Bag of Word)
5.1One-Hot方法
将所有的词使用编码的方式构造一个词典,词典中词的数量作为One-Hot编码的维度数,每个维度表示一个词,每个词在其对应的维度上出现时,该维度值为1。
优点:解决了词到数值空间的映射问题;编码不同,但是计算得到的结果相同;
缺点:没有考虑词的频率,使得任意两个词之间的距离相同;矩阵稀疏,维度可能太高,需要降维处理;没有考虑上下文,词被认为是独立的。
5.2Bag of Word(BoW)词袋模型
BoW方法思想:句子(或文档)由词组成,词出现的次数能够反映该句子的部分含义。
BoW方法:对所有的词构造词典,形成ID与词的映射。以词典大小作为向量维数,并统计句子(或文档)中每个词的出现频率,将词的频率填充到向量中对应的维度上得到该句子(或文档)向量。
步骤:
- 构造词典,每个词给定唯一编码,如0:also,获得词典,大小为10;
- 统计词典中每个词在句子中出现的次数,如𝑠1中movies次数为2;
- 将不同词出现的次数,填充到对应的维度上,得到最终向量。

优点:考虑了词频特征,能够更好地反映词在句子或文档中的分布情况;基于统计的特征提取,通用性更好;简单易用,有一定可用性和有效性;
缺点:不考虑词序特征、文法、句法特征,有信息丢失;矩阵(向量)稀疏,运算量大;
4.3TF-IDF
词频(Term Frequency, TF)定义:某个词在语料库中出现的频率,用以表示语料库中各词的分布情况。
逆文本频率(Inverse Document Frequency, IDF)

TF-IDF基于Zipf定律:在一个自然语言语料库中,单词的出现频率与它在频率排名中的位置(即排名靠前的单词出现的频率较高)成反比。具体来说,若将单词按频率排序,排名第一的单词出现的次数大约是排名第二的单词的两倍,排名第二的单词的出现次数大约是排名第三的单词的两倍,以此类推。
基于上述定律:𝑇𝐹 − 𝐼𝐷𝐹(w)= 𝑇𝐹(w)×𝐼𝐷𝐹(w)
TF-IDF能够反映文档中词对文档的贡献度,那么其能应用在哪些领域呢?
- 文本挖掘领域(Text Mining);
- 信息检索领域(InformationRetrieval)
TF-IDF的问题:
- 忽略了位置信息,不能完全地进行语义建模;
- 假设词是独立的,没有考虑上下文信息;
- 无法处理在文章中出现次数少,但是确是文档内容核心的情况;
4.4.主题模型
主题模型(Topic Model):一种以非监督学习的方式对文集的隐含语义结构进行聚类的统计模型。
TF-IDF在主题模型中的应用: 计算文档中各词的TF-IDF值,选取TF-IDF高的词作为文档的主题表示。
方法:
- 构建词典;
- 统计各词在文档、语料库中的TF值及IDF值;
- 计算TF-IDF值,并倒排序;
- 选取TF-IDF值高的项,并在词典中查找对应词,作为主题词。
4.5词项-文档矩阵(Term-Document Matrix)
词项-文档矩阵(Term-Document Matrix):通过计算TF-IDF值,来构建矩阵,矩阵中的每个元素值代表了相应行上的词项对应于相应列上的文档的权重,即这个词对于这篇文章来说的重要程度。
基本过程:
- 读入文档
- 分词
- 建立字典(得到ID:词的映射,ID将作为矩阵行的索引)
- 计算TF-IDF值
- 得到Term-Document Matrix
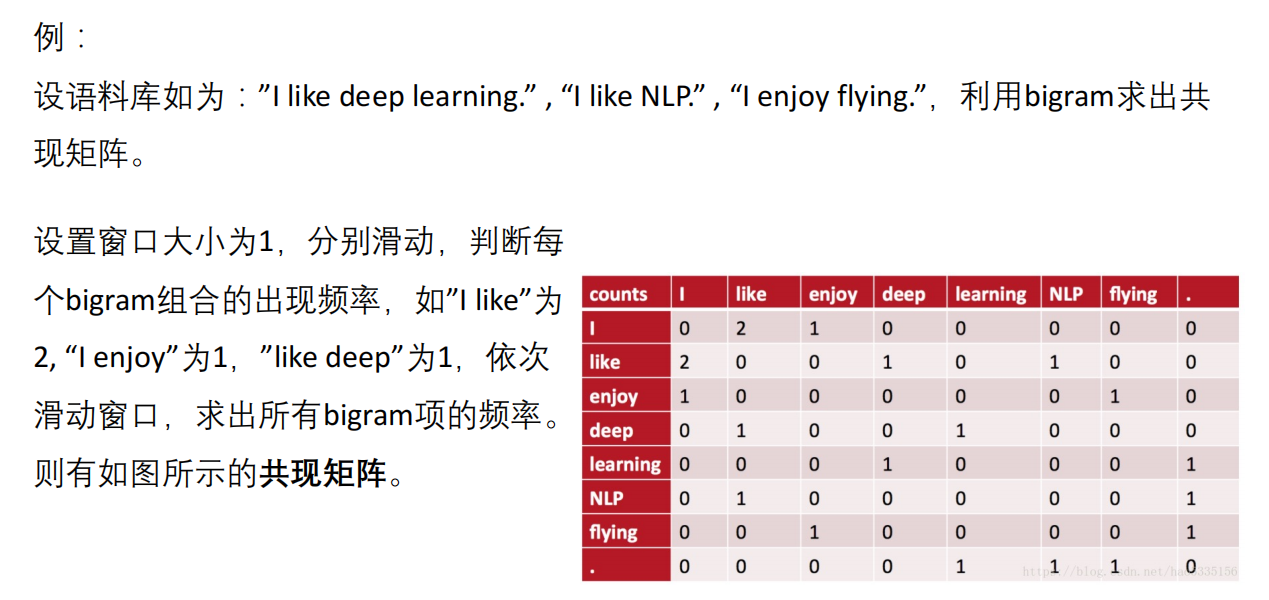
4.6共现矩阵
前面我们提到,TF-IDF和One-Hot编码均有一个弊端:认为词是独立存在,不考虑词的位置信息及上下文信息。 反观N-Gram模型,其建模了词与词之间的关联关系,如2-gram模型中,一个词将考虑 其前一个词的关系,这便是共现特征。
共现矩阵是基于N-Gram思想的又一种模型,其统计了一个词与其他词共同出现的频率,以此来建模词的特征。